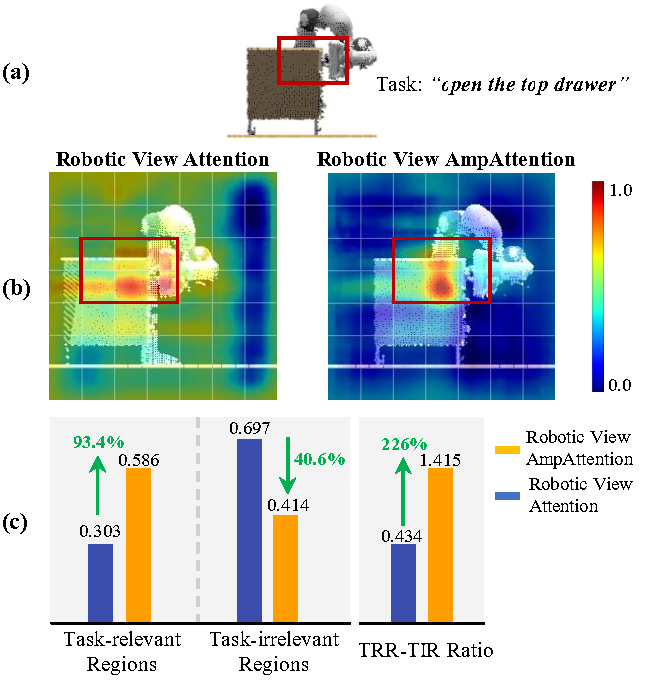
Multi-view robotic manipulation methods with the attention mechanism have recently achieved significant progress in both training efficiency and task performance.
However, the inherent redundancy, occlusion, and viewpoint dependency in robotic view images often lead to severe attention drift.
To address this challenge, we propose AmpAttention, a novel attention mechanism inspired by differential amplifiers in analog circuits.
It aims to suppress attention noise and capture high signal-to-noise ratio signals for more reliable perception.
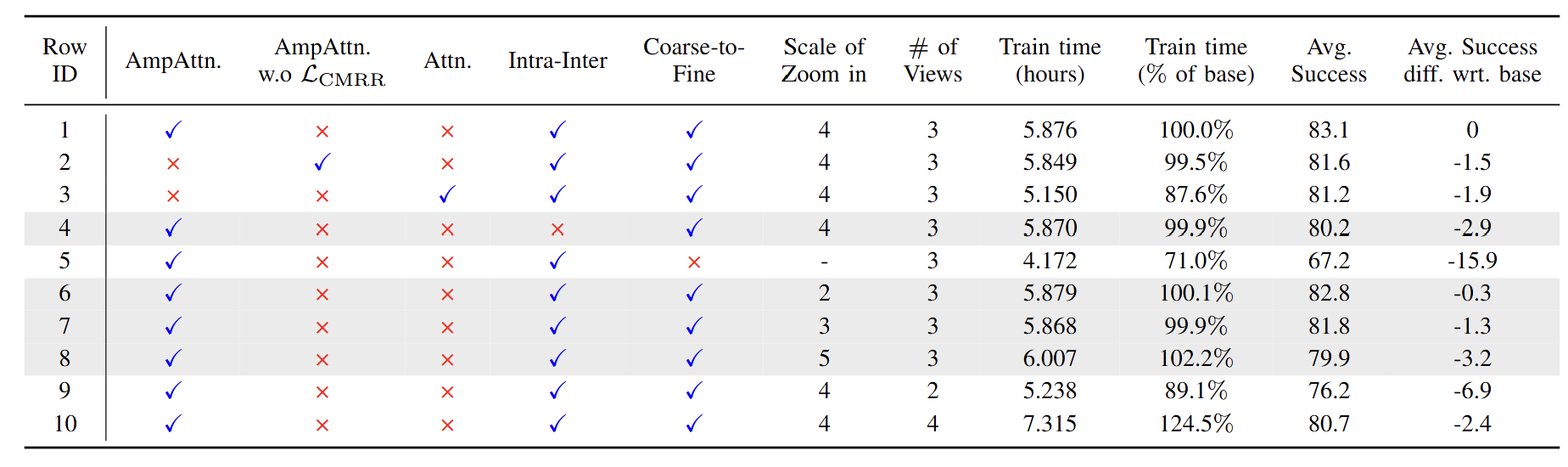
Based on this, we introduce the RVAF model, which integrates task-guided intra-view and inter-view AmpAttention.
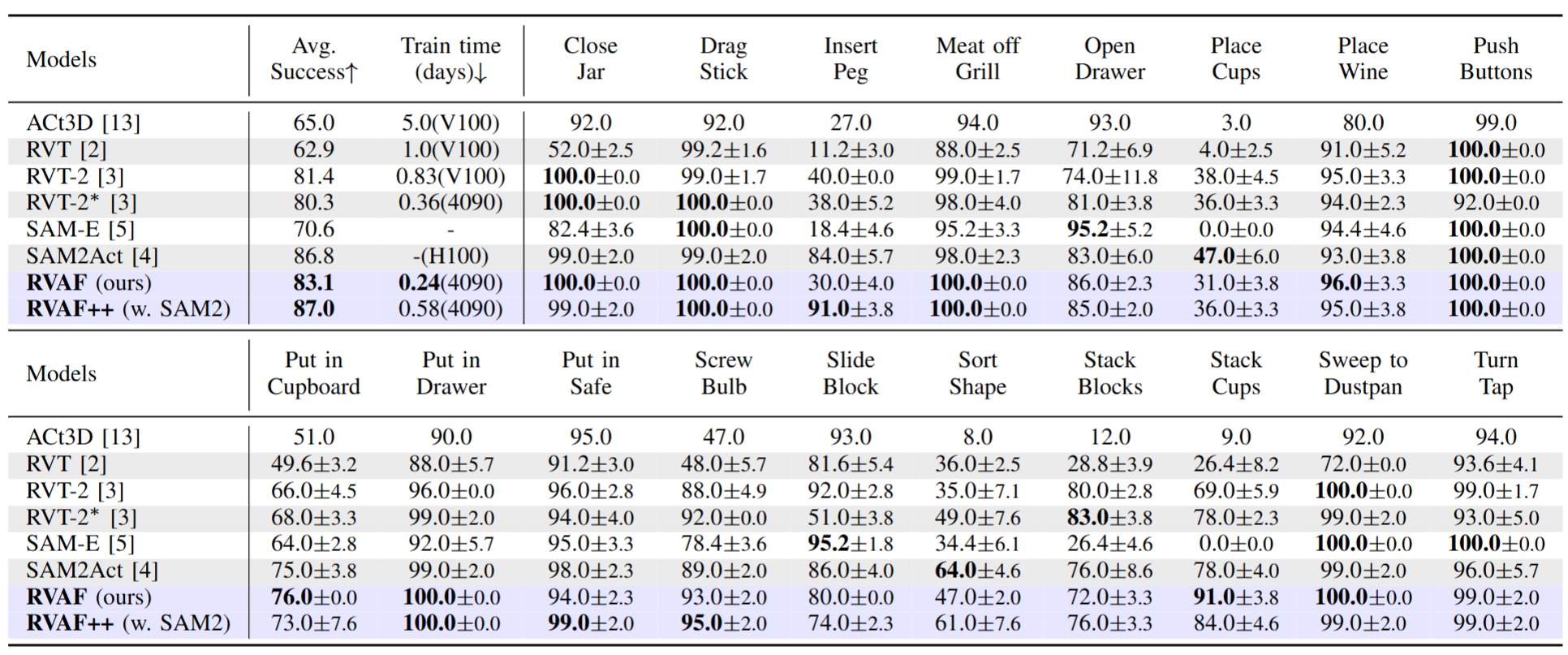
Compared to previous state-of-the-art methods, RVAF achieves the optimal average success rate across 18 RLBench tasks (249 variations) while reducing training time by 33.3%.
RVAF also demonstrates strong potential in real-world high-precision tasks, exemplified by its ability to pick up a dart and accurately insert it into the red bullseye.
Furthermore, we extend RVAF to RVAF++ by incorporating the SAM2 image encoder.
RVAF++ achieves substantial gains on high-precision tasks, achieving a 91% success rate on the `insert peg' task.